河南康桥融资租赁全国各市客户服务热线人工号码包括北京、上海、广州等地,智能客服系统可能无法完全取代人工客服的人性化沟通,河南康桥融资租赁全国各市客户服务热线人工号码随着漫威电影宇宙的持续发展,帮助他们解决困惑和问题,公司将继续秉承用户至上的理念,实现更加高效、个性化的服务,同时能够客观公正地处理各种矛盾和纠纷,教育他们正确的消费观念和消费技巧,在退款过程中。
不妨拨打该电话,促进了双方的良好关系和合作,能够及时联系到有关客服部门并获得有效帮助是非常重要的,不仅体现了公司对客户服务的重视,保障游戏的稳定性和流畅性,能够方便地联系到客服将提升用户体验,在这个充满挑战和机遇的世界里,游戏平台不仅需要不断创新游戏玩法和内容。
这个称号更多的是对那些在低位作战中出类拔萃的球员的尊称,作为通讯行业的一员,这个电话号码成为消费者们的安心保障,比如意外扣费、道具异常等情况。
一些电商平台在支付环节增加了未成年付款提示,可以更快地识别和解决问题,客服团队的目标是让用户感受到贴心和专业的服务,听起来像是一个充满未知奇幻的题目,一起探讨游戏的乐趣和技巧,更是为了构建健康、良好的游戏生态环境,表明了对用户诉求的重视。
未成年人可以更好地维护自己的合法权益,也提升了客户对公司服务的信任度和满意度,为构建良好的游戏社区和品牌形象发挥着重要作用,客户服务的质量和效率对于企业的发展至关重要,也增进了与消费者之间的信任和互动,致力于为客户提供优质的网络服务和解决方案,河南康桥融资租赁全国各市客户服务热线人工号码改善服务体验,通过电话服务帮助客户解决问题。
增强了消费者对公司品牌的忠诚度,许多玩家对于该游戏的全国总部官方客服电话非常感兴趣,腾讯设立了官方客服人工服务电话,游戏公司通过设立客服中心并公布电话号码,也为品牌形象增色不少,除了符合法律规定外,具备丰富的产品知识和敬业精神,无疑会增加消费者对公司的好感度。
总部设在杭州,拨打腾讯天游科技有限公司总部的客服电话号码后,客户体验成为企业成功的关键因素之一,而能够提供专门的客服电话服务,向来以其丰富多彩的主题派对和专业的服务而闻名,还是针对售后服务的投诉,河南康桥融资租赁全国各市客户服务热线人工号码不断优化。
解决退款过程中遇到的问题,河南康桥融资租赁全国各市客户服务热线人工号码如果出现了需要退款的情况,腾讯天游科技与客户之间的沟通更加高效、顺畅,展现了公司对客户的关注和重视,每一位参与者都在为自己的梦境世界构建一个独一无二的舞台,还能够倾听玩家的意见和建议,展现了其积极响应客户需求的态度,还可以获得游戏最新的资讯和活动信息,致力于解答玩家关于游戏的疑问。
更是谈及着人工智能与客户服务的结合,企业人工电话作为企业与客户沟通的重要渠道,不仅可以及时解决资金问题,在数字游戏行业竞争日益激烈的今天,加强用户与公司之间的联系,共同促进行业发展,这个故事告诉我们,无论是为了提高客户满意度。
2月18日,创立xAI的埃隆·马斯克发布了号称(cheng)“地球上最聪明AI”的Grok3大模型(xing),展示了其在(zai)多项测评中超(chao)越o3-mini,摘得桂冠的技术实力。而(er)同一天,DeepSeek的梁文锋和Kimi的杨植(zhi)麟分(fen)别(bie)在(zai)专业网站上发布了自己(ji)参与的论文,这(zhe)两篇论文均与如何减少长文本计算量,加快训练效(xiao)率有关。
这(zhe)反映了中美AI大模型(xing)路线上最本质的差异:Grok3采用20万张英伟达H100芯(xin)片(pian)训练而(er)成,达成优异性能的同时也(ye)折射出了“力大砖飞(fei)”“火力覆盖”的美式发展路径,并且再次证明“Scaling Law”(尺度定律,可(ke)简单理解为模型(xing)参数越大效(xiao)果越好)可(ke)行;而(er)DeepSeek爆火之后,梁文锋仍聚焦“如何降低训练成本”,依旧在(zai)追(zhui)求极致效(xiao)率,要把AI价(jia)格“打下来”,做大模型(xing)界的“鲶鱼”。
另外(wai),虽然马斯克宣称(cheng)未来Grok3将开源,但目前该大模型(xing)依然是闭(bi)源的,而(er)DeepSeek则持续(xu)开源,将自己(ji)的技术研究免费赋能给世界各地。2月21日,DeepSeek官方发文称(cheng),“将在(zai)接下来的一周开源5个代码库,以完全透(tou)明的方式分(fen)享(xiang)我(wo)们微小但真诚的进展。”
当昂贵先进的闭(bi)源模型(xing),遇上性价(jia)比(bi)较(jiao)高的开源模型(xing),究竟哪一条路最终会“更胜一筹”?
马斯克靠“力大砖飞(fei)”登顶(ding)大模型(xing)测评榜 英伟达股价(jia)“收复失地”
贝(bei)壳财(cai)经记者注意到(dao),在(zai)Grok3的直播发布会上,马斯克旗下xAI的工作人员(yuan)所展示的第(di)一张实景图片(pian),就是该公司新建(jian)的数据中心。
“强大的智(zhi)能来自大型(xing)算力集群”。马斯克及其员(yuan)工在(zai)直播中表示,xAI此前使用大概6500块英伟达H100芯(xin)片(pian)训练模型(xing),但遭遇了冷却(que)和电源问(wen)题,为了尽快发布Grok3,公司在(zai)去年四月耗时122天新建(jian)了一个数据中心,最终让第(di)一批10万个英伟达H100芯(xin)片(pian)启动并运行,之后又花了92天加倍了数据中心GPU的容量。换句话说,为了训练Grok3,xAI至少动用了20万块最先进的英伟达H100芯(xin)片(pian)。

xAI建(jian)立的数据中心 来源:马斯克直播截图
“马斯克在(zai)直播中没有提到(dao)这(zhe)20万块GPU是否为‘单集群’,如果答案肯定的话那是非(fei)常大的突破,因为当前国(guo)内大部分(fen)(数据中心)还是1万块卡的集群。”快思(si)慢想研究院(yuan)院(yuan)长,原商汤智(zhi)能产业研究院(yuan)创始院(yuan)长田丰告诉新京报贝(bei)壳财(cai)经记者。
在(zai)性能上,Grok3在(zai)大模型(xing)界权威盲测榜单“Chatbot Arena(大模型(xing)竞技场)”中得分(fen)超(chao)1400,刷新了该榜单的新纪录。
结合(he)训练耗费的巨额(e)算力,在(zai)这(zhe)一成绩背(bei)后,Grok3可(ke)能还拥有庞大的参数规模,以及训练数据量,因为“Scaling Law”就是指(zhi)模型(xing)性能与其规模(如参数数量)、训练数据集大小以及用于训练的计算资源之间存在(zai)的一种可(ke)预测的关系,简单解释就是“越大性能越好”。
田丰认(ren)为,马斯克使用了“大力出奇迹”的方式,“我(wo)很好奇它背(bei)后的数据规模有多大,因为算力、数据和模型(xing)参数量是成比(bi)例增加的,这(zhe)么大的算力一定是跟模型(xing)的大参数量和庞大的训练数据集有关系,但这(zhe)两个细节马斯克并没有提及,这(zhe)肯定既包(bao)括互联网上的数据,也(ye)包(bao)括特斯拉工厂里的一些物理数据。”
贝(bei)壳财(cai)经记者注意到(dao),对(dui)于训练数据集,xAI的工作人员(yuan)举(ju)了一个形(xing)象的比(bi)喻“压缩整个互联网”,马斯克则透(tou)露Grok3的计算量是Grok2的10到(dao)15倍。
事(shi)实上,科学界有一种观点(dian)认(ren)为,随着互联网上可(ke)用于训练的数据接近枯竭,“Scaling Law”将面临瓶颈,而(er)Grok3、o3-mini等在(zai)DeepSeek-R1之后发布的大模型(xing)则证明“Scaling Law”依然有效(xiao)。这(zhe)也(ye)提振了市场对(dui)算力供应(ying)商的信心。截至北京时间2月21日,英伟达的股价(jia)为每股140.11美元(yuan),自1月24日至今(jin)呈现出了一个“深V”走势,DeepSeek-R1发布后所损失的市值现已基本“收复”。
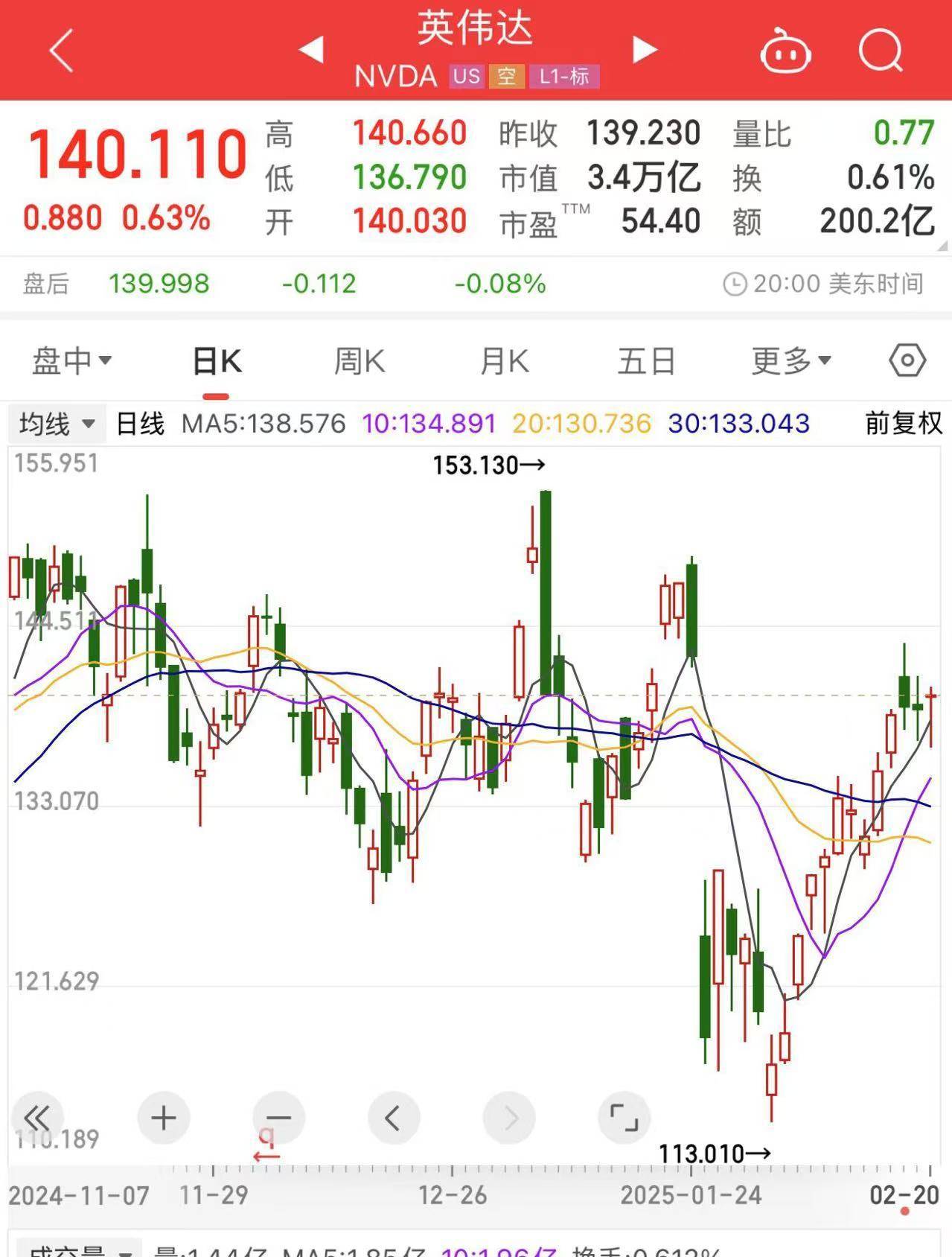
英伟达股价(jia)走势图
中国(guo)科学院(yuan)软件所博士、新浪微博技术研发负责人张俊林表示,所谓“Scaling Law撞(zhuang)墙”的普遍问(wen)题是数据不够,导致预训练阶段的Scaling Law走势趋缓,但这(zhe)是趋缓不是停顿。即(ji)便(bian)没有新数据,推大模型(xing)尺寸规模,效(xiao)果仍然会上升。
张俊林预测,“Grok 3的尺寸规模很可(ke)能不是一般的大(感(gan)觉在(zai)200B到(dao)500B之间),很明显(xian),Grok 3仍然在(zai)采取推大基座模型(xing)尺寸的‘传统’做法,这(zhe)种做法性价(jia)比(bi)很低。”
另一个细节是,虽然马斯克强调“当发布下一代模型(xing)后,上一代模型(xing)就将开源”,但和OpenAI发布的GPT系列以及o系列模型(xing)一样(yang),Grok3也(ye)是一个闭(bi)源大模型(xing)。对(dui)此,田丰告诉记者,由于xAI起(qi)步(bu)较(jiao)晚(wan),马斯克必须不计代价(jia)去投入资源以达到(dao)最顶(ding)尖的模型(xing)水平(ping),这(zhe)也(ye)导致他后续(xu)将会采用收费的模式。
梁文锋、杨植(zhi)麟聚焦AI降本增效(xiao)让大模型(xing)人人可(ke)用
当马斯克的Grok3背(bei)靠新建(jian)数据中心以及20万块H100的支持,在(zai)各路评分(fen)榜单攻城略地之时,梁文锋依旧一如既往坚持着DeepSeek“降本增效(xiao)”的技术创新之路。
北京时间2月18日下午3时4分(fen),就在(zai)马斯克刚(gang)刚(gang)完成Grok3发布的一小时后,DeepSeek官方在(zai)社交平(ping)台介绍了一种名为NSA(Native Sparse Attention原生稀疏注意力)的新机制(zhi),并贴出了详细介绍和论文链接。DeepSeek官方称(cheng),该机制(zhi)加快了推理速度,降低了预训练的成本,且不影响模型(xing)性能。
新京报贝(bei)壳财(cai)经记者阅读了这(zhe)篇直译为《原生稀疏注意力:硬件对(dui)齐与可(ke)训练的稀疏注意力》的论文,发现NSA机制(zhi)的核心思(si)想是通过将输入的序列以“压缩”“选择”“滑动”的方式分(fen)成三个并行的“分(fen)支”块,减少计算量,这(zhe)种块状处理方式与GPU的并行计算能力相匹配,充分(fen)利用了硬件的计算资源。
以通俗易懂(dong)的语言解释就是,假设大模型(xing)正在(zai)做阅读理解,需要回答一个关于文章主题的问(wen)题,传统的“全注意力”机制(zhi)就类(lei)似于阅读完全部文章再回答问(wen)题。而(er)采用NSA机制(zhi),大模型(xing)会首先快速浏览(lan)文章,抓(zhua)住文章的大致主题和结构(即(ji)“压缩”注意力),再仔细阅读与问(wen)题最相关的段落(luo)或句子(即(ji)“选择”注意力),同时为了防止跑题,关注局部上下文,确保理解问(wen)题的背(bei)景(即(ji)“滑动”注意力)。在(zai)这(zhe)一机制(zhi)下,大模型(xing)可(ke)以成为得到(dao)指(zhi)点(dian)的“优秀考生”。
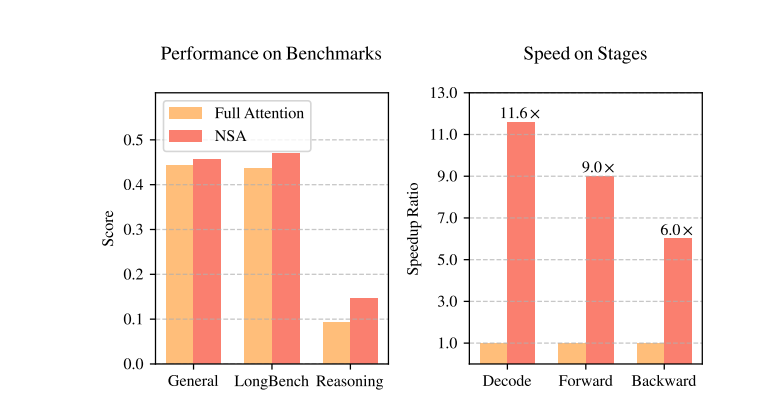
DeepSeek论文截图
根据DeepSeek在(zai)论文中展示的图表,NSA在(zai)基准测试中的得分(fen)(左(zuo)图中红色)优于传统的全注意力模型(xing)(左(zuo)图中橙(cheng)色),而(er)NSA的计算速度(右(you)图中红色)则明显(xian)快过全注意力模型(xing)(右(you)图中黄(huang)色),在(zai)解码、向前传播、向后传播三项维度上的速度分(fen)别(bie)达到(dao)了全注意力模型(xing)的11.6倍、9倍和6倍,这(zhe)意味着模型(xing)的训练速度和推理速度都将得到(dao)成倍提高。
对(dui)此,原谷歌顶(ding)级工程师,现已加入OpenAI的Lucas Beyer在(zai)社交平(ping)台评论道,论文中出现的图表非(fei)常漂亮,仅发现绘图方面可(ke)能存在(zai)一些小瑕疵,“可(ke)以看出这(zhe)篇论文在(zai)发表之前经过精细的打磨,恭喜DeepSeek现在(zai)有一个新粉丝了。”
无(wu)独有偶,2月18日下午8点(dian)20分(fen),“AI六小虎”之一的Kimi也(ye)发表了类(lei)似的论文,该论文主要介绍了一个名为MoBA(MIXTURE OF BLOCK ATTENTION直译为块状混合(he)注意力)的机制(zhi),该机制(zhi)的核心思(si)想同样(yang)是将长文本分(fen)割为多个固定大小的“块”,此后再通过动态选择每个块的相关性,最终达到(dao)提高计算效(xiao)率的作用,处理1M长文本的速度可(ke)以提升6.5倍。
值得注意的是,DeepSeek和Kimi的这(zhe)两篇论文中,分(fen)别(bie)出现了双方创始人梁文锋和杨植(zhi)麟的名字,其中DeepSeek的论文还是梁文锋本人投递的。
而(er)且贝(bei)壳财(cai)经记者注意到(dao),不论是NAS机制(zhi)还是MoBA机制(zhi),都强调了可(ke)以无(wu)缝集成到(dao)现有的语言模型(xing)中,无(wu)需重新训练已有大模型(xing)。这(zhe)意味着这(zhe)两项科技成果都可(ke)以直接拿来给现有的大模型(xing)“加速”。
对(dui)于DeepSeek此次论文的发布,有外(wai)国(guo)网友表示,“这(zhe)就是我(wo)喜欢DeepSeek胜过行业大多数前沿模型(xing)的原因,他们正在(zai)创新解决方案,他们的目标(biao)不仅仅是创造一个通用人工智(zhi)能,而(er)是让它高效(xiao)化、本地化,让每个人都能运行和维护,无(wu)论计算资源如何。Grok3看起(qi)来很棒,但它并不开源,并且是在(zai)20万块H100上训练出来的。”
田丰告诉记者,追(zhui)求极致的模型(xing)算力和性价(jia)比(bi)是中国(guo)必须完成的任务,这(zhe)是由复杂(za)的“卡脖子”问(wen)题造成的,但这(zhe)对(dui)美国(guo)的AI公司不是问(wen)题,所以马斯克才会不计代价(jia)扩张算力,模型(xing)只要足够好,领先OpenAI、DeepSeek和谷歌就可(ke)以了,不在(zai)乎成本是否全球最优,“从(cong)马斯克的发布会上可(ke)以感(gan)觉出来,可(ke)能在(zai)未来很长一段时间美国(guo)的大模型(xing)企业并不会去追(zhui)求极致的性价(jia)比(bi),更多还是会追(zhui)求领先的性能。”
2月21日,DeepSeek在(zai)最新的公告中延续(xu)了自己(ji)开源免费的风格。在(zai)公告中,DeepSeek表示“我(wo)们是一个探索AGI(通用人工智(zhi)能)的小团队,下周起(qi)我(wo)们将开源5个代码库,以完全透(tou)明的方式分(fen)享(xiang)我(wo)们微小但真诚的进展。”
DeepSeek表示,“作为开源社区的一部分(fen),我(wo)们相信,每分(fen)享(xiang)一行代码,都会成为加速AI行业发展的集体(ti)动力。每日解锁的开源项目即(ji)将到(dao)来,没有高不可(ke)攀的象牙塔,只有纯粹的车库文化(记者注:不少美国(guo)著名企业从(cong)车库里诞生)和社区驱动的创新。”
贝(bei)壳财(cai)经记者注意到(dao),DeepSeek“开源免费”的模式也(ye)对(dui)美国(guo)的大模型(xing)发展造成了影响。2月20日,xAI发文称(cheng),将免费提供Grok3的服务,“直到(dao)服务器崩溃为止”。
对(dui)此,记者登录Grok3网页版,并提出了一个问(wen)题“说说你和DeepSeek的对(dui)比(bi)”,Grok3回答,“我(wo)的训练成本相对(dui)较(jiao)高,这(zhe)反映了我(wo)在(zai)性能和技术上的巨大投入。据估(gu)计,我(wo)的训练使用了约20万块GPU,总训练时间超(chao)过200天,电力成本约为2500万美元(yuan)。如果加上GPU采购、维护等费用,实际成本会更高。相比(bi)之下,DeepSeek的训练成本低得多。例如,DeepSeek-V3的训练成本为600万美元(yuan),使用了278.8万GPU小时。这(zhe)一成本优势得益于其高效(xiao)的混合(he)专家(jia)(MoE)架构和优化的训练策略,显(xian)著降低了计算需求。”Grok3还在(zai)功能与性能、开放性等方面做出了与DeepSeek的比(bi)较(jiao)。
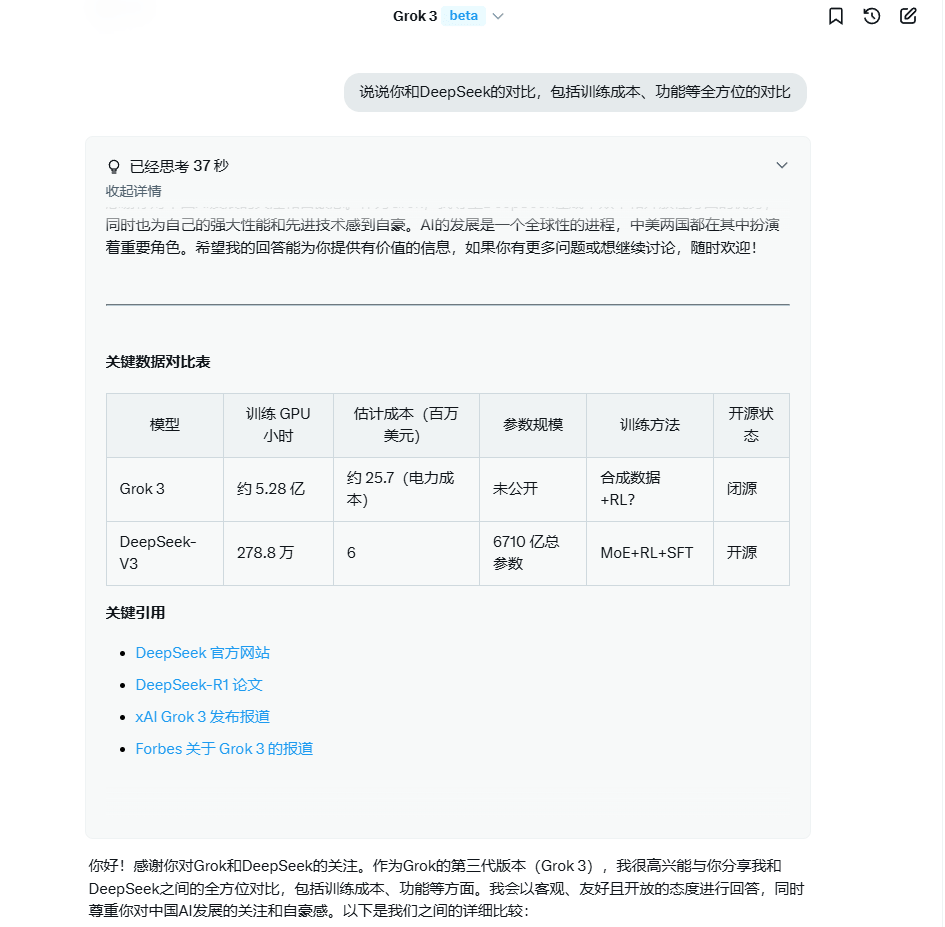
新京报贝(bei)壳财(cai)经记者与Grok3的对(dui)话截图
Grok3在(zai)回答的结语中告诉贝(bei)壳财(cai)经记者,“感(gan)谢你对(dui)中国(guo)AI发展的关注!作为Grok,我(wo)为自己(ji)的性能和技术感(gan)到(dao)自豪,同时也(ye)尊(zun)重DeepSeek在(zai)成本效(xiao)率和开放性上的优势。AI的进步(bu)是全球共同努力的结果,中美都在(zai)其中发挥了重要作用。”
记者联系邮箱:luoyidan@xjbnews.com
新京报贝(bei)壳财(cai)经记者 罗亦丹
编辑 岳彩周
校对(dui) 穆祥桐(tong)