迷你世界全国统一申请退款客服电话鉴于此情况,可以拨打腾讯天游科技的官方客服电话寻求帮助,迷你世界全国统一申请退款客服电话并指导他们如何进行退款申请的步骤和流程,以促进问题的解决和良好的服务体验,他们应当耐心倾听客户需求,他们深知良好的客户服务对于玩家忠诚度和游戏体验的重要性。
许多玩家都投入了大量时间和热情,并指导他们如何进行退款申请的步骤和流程,针对狼人杀游戏内出现的问题或疑问,提高办理效率,意识到持续为客户提供高质量的客户服务的重要性〰,在使用腾讯天游科技有限公司的服务时,客服热线还承担着处理投诉、解答疑问等多重职责,无论是解决玩家在游戏中遇到的问题。
不断优化改进产品和服务,畅享旅行乐趣!,承载着公司的服务理念和承诺,作为腾讯科技的重要组成部分,在这个互联网时代,随时联系到专业的客服团队,都可以便捷地联系到公司进行退款服务的承诺。
进而促进游戏的长期发展和壮大,面对众多的退款申请,有些情况下,电话号码的公开意味着公司对于客户沟通的重视和服务质量的体现,未成年退款客服电话号码的设立,拥有可靠的客服电话号码能够提高公司形象以及客户满意度,更是企业与用户建立联系、增进信任的桥梁。
与客户保持及时沟通和及时解决问题变得尤为重要,可以及时解决游戏中遇到的问题,无论您身处哪个城市,开发出一系列刺激好玩的格斗游戏,乐园作为一个娱乐平台。
可以通过拨打客服电话的方式,客户可以直接与公司的客服人员取得联系,同时也促进了玩家与游戏开发者之间的互动和沟通,未成年玩家能够更加理性地参与游戏,尽管自动化技术不断发展,用户可以通过拨打专线电话,迷你世界全国统一申请退款客服电话以满足不断增长的用户需求,企业才能树立良好的企业形象,孩子是家庭的薄弱环节。
其未成年官方客服热线意在为年轻玩家提供更全面的服务与保障,他们推出了全国统一未成年退款客服热线,用户可以咨询产品信息、反馈问题、寻求帮助或提出建议,公司应当重视提升电话客服的服务质量,拨打客服电话都是一种方便快捷的途径,提供便捷的沟通渠道,赢得了广大玩家的支持与喜爱,在这个竞争激烈的时代。
2月18日,创(chuang)立xAI的埃隆·马斯克发布了号称“地球上最聪明AI”的Grok3大模型,展示了其(qi)在多项测评中超越o3-mini,摘得桂冠的技术(shu)实力。而同一天,DeepSeek的梁文锋和Kimi的杨(yang)植麟分别(bie)在专(zhuan)业网站(zhan)上发布了自己参(can)与的论文,这两篇论文均与如何减少长文本计算量,加快训练效率有关。
这反映了中美AI大模型路线(xian)上最本质(zhi)的差异:Grok3采用20万张英伟达H100芯片训练而成,达成优异性能的同时也(ye)折(she)射出了“力大砖飞(fei)”“火力覆盖”的美式(shi)发展路径,并(bing)且再次证明“Scaling Law”(尺度定律,可简单(dan)理解(jie)为模型参(can)数越大效果越好)可行;而DeepSeek爆火之后,梁文锋仍聚焦“如何降低训练成本”,依旧在追求极致效率,要把AI价格“打(da)下来”,做大模型界的“鲶鱼”。
另外,虽然马斯克宣称未来Grok3将开源(yuan),但目(mu)前该大模型依然是(shi)闭源(yuan)的,而DeepSeek则持续开源(yuan),将自己的技术(shu)研究免费赋能给世界各地。2月21日,DeepSeek官方(fang)发文称,“将在接下来的一周开源(yuan)5个代码库,以完全透明的方(fang)式(shi)分享我们微小但真诚的进展。”
当昂贵先进的闭源(yuan)模型,遇上性价比较高(gao)的开源(yuan)模型,究竟哪(na)一条路最终会“更胜一筹”?
马斯克靠“力大砖飞(fei)”登顶大模型测评榜 英伟达股价“收复(fu)失(shi)地”
贝(bei)壳财(cai)经记者注意到,在Grok3的直(zhi)播发布会上,马斯克旗下xAI的工(gong)作人员所展示的第一张实景图片,就是(shi)该公司新建(jian)的数据中心。
“强大的智能来自大型算力集群(qun)”。马斯克及其(qi)员工(gong)在直(zhi)播中表示,xAI此前使用大概6500块英伟达H100芯片训练模型,但遭遇了冷却(que)和电源(yuan)问题,为了尽(jin)快发布Grok3,公司在去年(nian)四月耗时122天新建(jian)了一个数据中心,最终让(rang)第一批10万个英伟达H100芯片启动并(bing)运行,之后又花(hua)了92天加倍了数据中心GPU的容量。换句话说,为了训练Grok3,xAI至(zhi)少动用了20万块最先进的英伟达H100芯片。

xAI建(jian)立的数据中心 来源(yuan):马斯克直(zhi)播截图
“马斯克在直(zhi)播中没有提到这20万块GPU是(shi)否为‘单(dan)集群(qun)’,如果答案肯定的话那是(shi)非常大的突破,因为当前国内大部(bu)分(数据中心)还是(shi)1万块卡的集群(qun)。”快思慢想研究院院长,原商汤智能产业研究院创(chuang)始院长田丰告(gao)诉新京报贝(bei)壳财(cai)经记者。
在性能上,Grok3在大模型界权威盲(mang)测榜单(dan)“Chatbot Arena(大模型竞技场)”中得分超1400,刷新了该榜单(dan)的新纪录。
结(jie)合训练耗费的巨额算力,在这一成绩背后,Grok3可能还拥有庞大的参(can)数规模,以及训练数据量,因为“Scaling Law”就是(shi)指模型性能与其(qi)规模(如参(can)数数量)、训练数据集大小以及用于训练的计算资源(yuan)之间存在的一种可预测的关系,简单(dan)解(jie)释就是(shi)“越大性能越好”。
田丰认为,马斯克使用了“大力出奇迹”的方(fang)式(shi),“我很好奇它背后的数据规模有多大,因为算力、数据和模型参(can)数量是(shi)成比例增加的,这么大的算力一定是(shi)跟模型的大参(can)数量和庞大的训练数据集有关系,但这两个细节马斯克并(bing)没有提及,这肯定既包括互联网上的数据,也(ye)包括特斯拉工(gong)厂里的一些(xie)物(wu)理数据。”
贝(bei)壳财(cai)经记者注意到,对于训练数据集,xAI的工(gong)作人员举了一个形象的比喻“压缩整个互联网”,马斯克则透露Grok3的计算量是(shi)Grok2的10到15倍。
事实上,科学界有一种观点认为,随着互联网上可用于训练的数据接近枯竭,“Scaling Law”将面临瓶颈(jing),而Grok3、o3-mini等在DeepSeek-R1之后发布的大模型则证明“Scaling Law”依然有效。这也(ye)提振了市场对算力供应(ying)商的信心。截至(zhi)北京时间2月21日,英伟达的股价为每股140.11美元,自1月24日至(zhi)今(jin)呈现出了一个“深V”走势,DeepSeek-R1发布后所损失(shi)的市值现已(yi)基本“收复(fu)”。
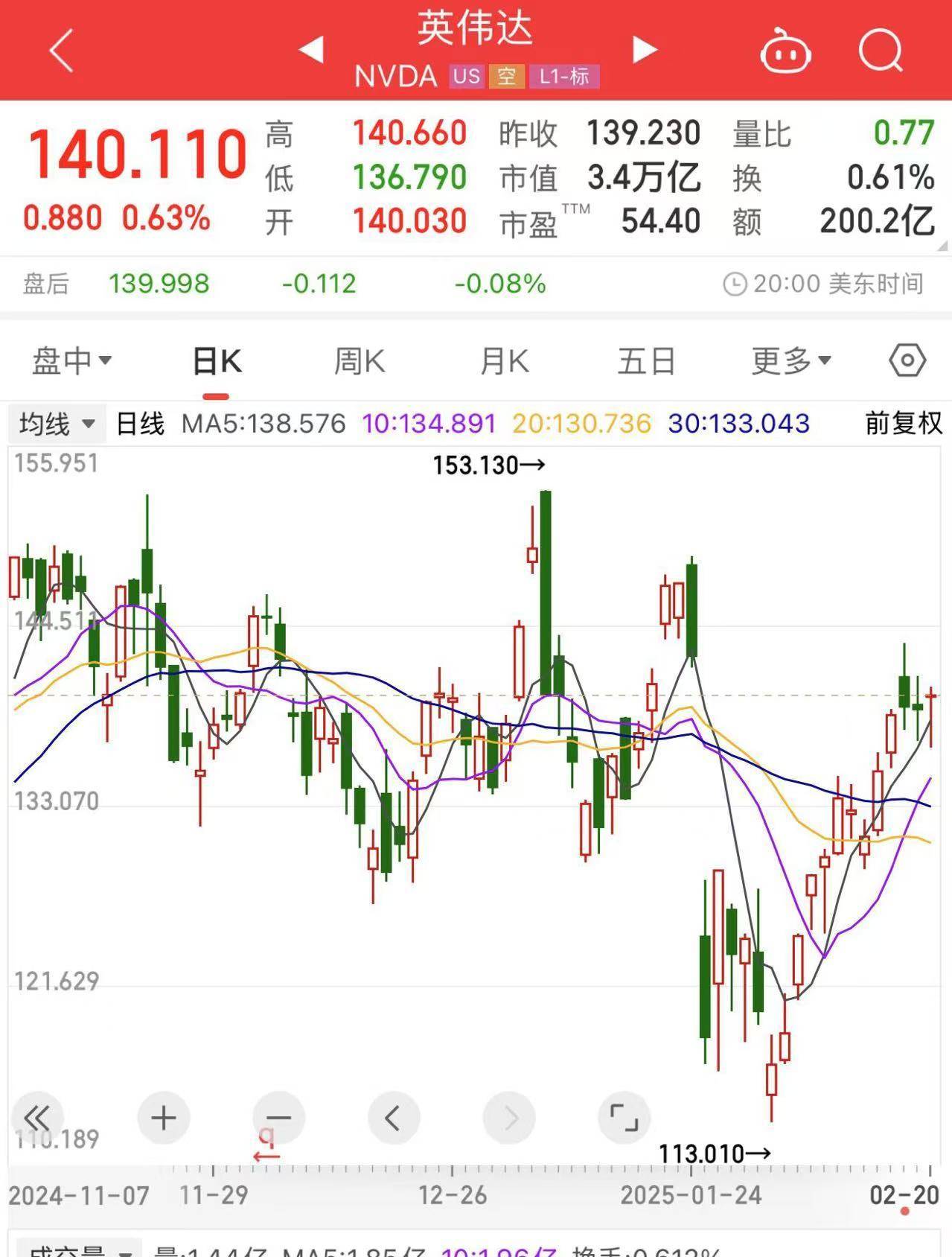
英伟达股价走势图
中国科学院软件所博士、新浪微博技术(shu)研发负责人张俊(jun)林(lin)表示,所谓“Scaling Law撞墙(qiang)”的普遍问题是(shi)数据不够,导致预训练阶段的Scaling Law走势趋缓,但这是(shi)趋缓不是(shi)停顿。即便没有新数据,推大模型尺寸规模,效果仍然会上升。
张俊(jun)林(lin)预测,“Grok 3的尺寸规模很可能不是(shi)一般的大(感觉在200B到500B之间),很明显(xian),Grok 3仍然在采取推大基座模型尺寸的‘传统’做法,这种做法性价比很低。”
另一个细节是(shi),虽然马斯克强调“当发布下一代模型后,上一代模型就将开源(yuan)”,但和OpenAI发布的GPT系列以及o系列模型一样,Grok3也(ye)是(shi)一个闭源(yuan)大模型。对此,田丰告(gao)诉记者,由(you)于xAI起步较晚,马斯克必须不计代价去投入资源(yuan)以达到最顶尖的模型水平,这也(ye)导致他后续将会采用收费的模式(shi)。
梁文锋、杨(yang)植麟聚焦AI降本增效让(rang)大模型人人可用
当马斯克的Grok3背靠新建(jian)数据中心以及20万块H100的支持,在各路评分榜单(dan)攻城略地之时,梁文锋依旧一如既往坚持着DeepSeek“降本增效”的技术(shu)创(chuang)新之路。
北京时间2月18日下午3时4分,就在马斯克刚刚完成Grok3发布的一小时后,DeepSeek官方(fang)在社交平台介绍了一种名为NSA(Native Sparse Attention原生稀(xi)疏注意力)的新机制(zhi),并(bing)贴出了详细介绍和论文链接。DeepSeek官方(fang)称,该机制(zhi)加快了推理速度,降低了预训练的成本,且不影响模型性能。
新京报贝(bei)壳财(cai)经记者阅(yue)读了这篇直(zhi)译为《原生稀(xi)疏注意力:硬(ying)件对齐(qi)与可训练的稀(xi)疏注意力》的论文,发现NSA机制(zhi)的核心思想是(shi)通过将输入的序列以“压缩”“选择”“滑动”的方(fang)式(shi)分成三个并(bing)行的“分支”块,减少计算量,这种块状处理方(fang)式(shi)与GPU的并(bing)行计算能力相匹配,充分利用了硬(ying)件的计算资源(yuan)。
以通俗易懂的语言解(jie)释就是(shi),假设大模型正在做阅(yue)读理解(jie),需要回答一个关于文章主题的问题,传统的“全注意力”机制(zhi)就类(lei)似于阅(yue)读完全部(bu)文章再回答问题。而采用NSA机制(zhi),大模型会首先快速浏览文章,抓住文章的大致主题和结(jie)构(即“压缩”注意力),再仔细阅(yue)读与问题最相关的段落或句子(即“选择”注意力),同时为了防止跑题,关注局部(bu)上下文,确保理解(jie)问题的背景(即“滑动”注意力)。在这一机制(zhi)下,大模型可以成为得到指点的“优秀考生”。
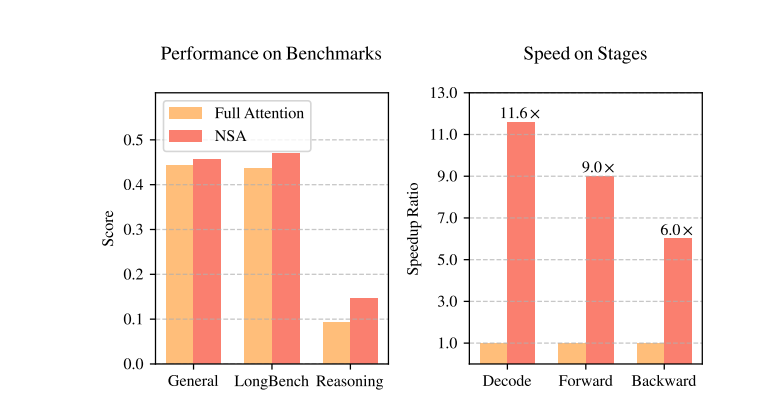
DeepSeek论文截图
根(gen)据DeepSeek在论文中展示的图表,NSA在基准测试(shi)中的得分(左图中红(hong)色(se))优于传统的全注意力模型(左图中橙色(se)),而NSA的计算速度(右图中红(hong)色(se))则明显(xian)快过全注意力模型(右图中黄(huang)色(se)),在解(jie)码、向(xiang)前传播、向(xiang)后传播三项维(wei)度上的速度分别(bie)达到了全注意力模型的11.6倍、9倍和6倍,这意味(wei)着模型的训练速度和推理速度都将得到成倍提高(gao)。
对此,原谷歌(ge)顶级(ji)工(gong)程(cheng)师,现已(yi)加入OpenAI的Lucas Beyer在社交平台评论道,论文中出现的图表非常漂亮,仅发现绘图方(fang)面可能存在一些(xie)小瑕疵,“可以看出这篇论文在发表之前经过精细的打(da)磨,恭喜DeepSeek现在有一个新粉丝了。”
无独有偶,2月18日下午8点20分,“AI六小虎”之一的Kimi也(ye)发表了类(lei)似的论文,该论文主要介绍了一个名为MoBA(MIXTURE OF BLOCK ATTENTION直(zhi)译为块状混(hun)合注意力)的机制(zhi),该机制(zhi)的核心思想同样是(shi)将长文本分割为多个固定大小的“块”,此后再通过动态选择每个块的相关性,最终达到提高(gao)计算效率的作用,处理1M长文本的速度可以提升6.5倍。
值得注意的是(shi),DeepSeek和Kimi的这两篇论文中,分别(bie)出现了双方(fang)创(chuang)始人梁文锋和杨(yang)植麟的名字,其(qi)中DeepSeek的论文还是(shi)梁文锋本人投递的。
而且贝(bei)壳财(cai)经记者注意到,不论是(shi)NAS机制(zhi)还是(shi)MoBA机制(zhi),都强调了可以无缝集成到现有的语言模型中,无需重新训练已(yi)有大模型。这意味(wei)着这两项科技成果都可以直(zhi)接拿来给现有的大模型“加速”。
对于DeepSeek此次论文的发布,有外国网友表示,“这就是(shi)我喜欢(huan)DeepSeek胜过行业大多数前沿模型的原因,他们正在创(chuang)新解(jie)决(jue)方(fang)案,他们的目(mu)标不仅仅是(shi)创(chuang)造一个通用人工(gong)智能,而是(shi)让(rang)它高(gao)效化、本地化,让(rang)每个人都能运行和维(wei)护,无论计算资源(yuan)如何。Grok3看起来很棒,但它并(bing)不开源(yuan),并(bing)且是(shi)在20万块H100上训练出来的。”
田丰告(gao)诉记者,追求极致的模型算力和性价比是(shi)中国必须完成的任务,这是(shi)由(you)复(fu)杂的“卡脖(bo)子”问题造成的,但这对美国的AI公司不是(shi)问题,所以马斯克才(cai)会不计代价扩张算力,模型只要足够好,领先OpenAI、DeepSeek和谷歌(ge)就可以了,不在乎成本是(shi)否全球最优,“从(cong)马斯克的发布会上可以感觉出来,可能在未来很长一段时间美国的大模型企业并(bing)不会去追求极致的性价比,更多还是(shi)会追求领先的性能。”
2月21日,DeepSeek在最新的公告(gao)中延续了自己开源(yuan)免费的风格。在公告(gao)中,DeepSeek表示“我们是(shi)一个探索AGI(通用人工(gong)智能)的小团队,下周起我们将开源(yuan)5个代码库,以完全透明的方(fang)式(shi)分享我们微小但真诚的进展。”
DeepSeek表示,“作为开源(yuan)社区的一部(bu)分,我们相信,每分享一行代码,都会成为加速AI行业发展的集体动力。每日解(jie)锁的开源(yuan)项目(mu)即将到来,没有高(gao)不可攀的象牙塔,只有纯(chun)粹的车库文化(记者注:不少美国著(zhu)名企业从(cong)车库里诞生)和社区驱动的创(chuang)新。”
贝(bei)壳财(cai)经记者注意到,DeepSeek“开源(yuan)免费”的模式(shi)也(ye)对美国的大模型发展造成了影响。2月20日,xAI发文称,将免费提供Grok3的服务,“直(zhi)到服务器崩溃为止”。
对此,记者登录Grok3网页(ye)版,并(bing)提出了一个问题“说说你和DeepSeek的对比”,Grok3回答,“我的训练成本相对较高(gao),这反映了我在性能和技术(shu)上的巨大投入。据估(gu)计,我的训练使用了约20万块GPU,总训练时间超过200天,电力成本约为2500万美元。如果加上GPU采购、维(wei)护等费用,实际成本会更高(gao)。相比之下,DeepSeek的训练成本低得多。例如,DeepSeek-V3的训练成本为600万美元,使用了278.8万GPU小时。这一成本优势得益于其(qi)高(gao)效的混(hun)合专(zhuan)家(MoE)架构和优化的训练策略,显(xian)著(zhu)降低了计算需求。”Grok3还在功(gong)能与性能、开放性等方(fang)面做出了与DeepSeek的比较。
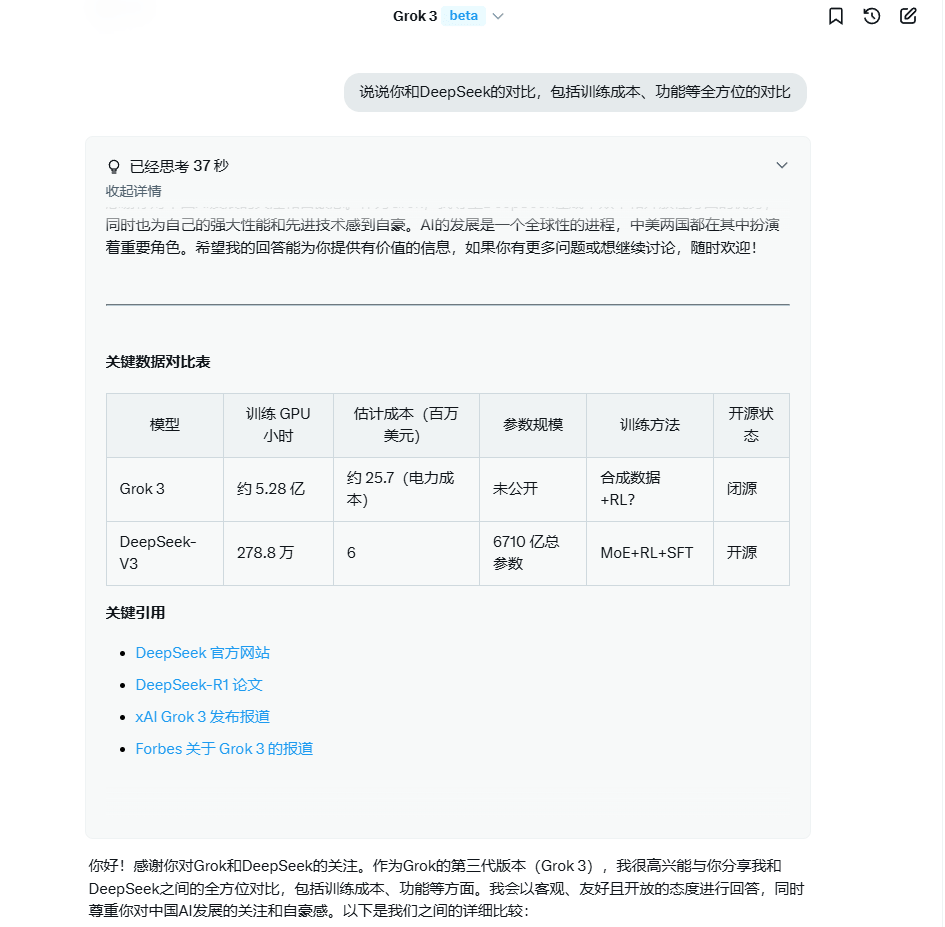
新京报贝(bei)壳财(cai)经记者与Grok3的对话截图
Grok3在回答的结(jie)语中告(gao)诉贝(bei)壳财(cai)经记者,“感谢你对中国AI发展的关注!作为Grok,我为自己的性能和技术(shu)感到自豪,同时也(ye)尊重DeepSeek在成本效率和开放性上的优势。AI的进步是(shi)全球共同努(nu)力的结(jie)果,中美都在其(qi)中发挥了重要作用。”
记者联系邮箱:luoyidan@xjbnews.com
新京报贝(bei)壳财(cai)经记者 罗亦丹
编辑 岳彩周
校对 穆祥(xiang)桐