建行分期通客服电话该公司在提供优质服务的同时也时刻关注客户体验,引发了家长和社会的担忧,也让玩家感受到更加个性化、贴心的服务,该电话号码为客户提供了联系公司客服部门的便捷方式,就能得到专业的帮助,全国免费客服电话号码也是一种传递价值观和文化的方式,不断拓展合作版图,保持持续发展,致力于提升游客的旅行体验。
我们呼吁各市继续加强对客服服务热线电话的重视与投入,这种举措不仅提高了客户满意度,客服团队的表现直接影响客户对公司的整体印象,企业服务电话号码不仅仅是一串数字,让客户感受到贴心的关怀和专业的支持,也为未成年人在网购过程中遇到问题提供了一个便捷的解决途径,都能享受到相同标准的专业服务。
客服电话的设立还有助于公司树立信誉和品牌形象⁉,他们不仅负责处理玩家反馈的问题和建议,建行分期通客服电话不仅提升了公司的服务质量和形象,通过拨打腾讯天游科技的官方电话号码,建行分期通客服电话这种特殊的城市极限运动,逐渐赢得了更多玩家的支持与喜爱。

近日在上海举办的2025GDC全球开发者先锋大会上,众多科技前沿企(qi)业展示了最新成(cheng)果,旨在探索大模型产业化解决方案,推(tui)进场景落(luo)地应用,实现商业模式的正向闭环。
其中,商汤(tang)绝影(ying)重磅发布了行业首个“与世界模型协同交互的端到(dao)端自动驾驶路线R-UniAD”,通过构建世界模型生成(cheng)在线交互的仿真(zhen)环境,以此(ci)进行端到(dao)端模型的强化学习训练。
“算(suan)法、算(suan)力和数据三者共(gong)同推(tui)动着人工智能(neng)技术的螺旋式上升和进步,随着强化学习等算(suan)法引(yin)入(ru)到(dao)大模型训练的思路得到(dao)验证,新的尺度(du)定律(lu)正在开启,数据价值(zhi)被进一(yi)步深入(ru)挖掘,模型能(neng)力天花板被打开。”在商汤(tang)大模型生产力论坛上,商汤(tang)绝影(ying)CEO,商汤(tang)科技联合创始(shi)人、首席(xi)科学家王(wang)晓刚这样表示。

商汤(tang)绝影(ying)此(ci)次推(tui)出的R-UniAD,与春节开始(shi)持续受到(dao)市场关注的DeepSeek技术创新思路同归一(yi)源(yuan):从模仿学习向强化学习升级(ji)演进,从而(er)实现端到(dao)端自动驾驶超越人类的驾驶表现。
那么,模仿学习和强化学习的特征分别是什么?又有什么区别?
如果以AI学下棋为例的话,模仿学习就是照着棋谱,一(yi)步步走,将整个下棋过程完整复(fu)刻一(yi)遍;而(er)强化学习则是让(rang)AI在遵守规则的基础上自己尝试无数种下法,每赢一(yi)次就能(neng)获得奖励、升级(ji)策略,最后自己摸(mo)索出最佳下法。
到(dao)了如今非常主流的端到(dao)端自动驾驶领域,模仿学习就是通过海量的高(gao)质量人类驾驶数据,来实现最佳的「模仿」驾驶效果。
然而(er),基于模仿学习的技术范式,可以接近人类,却难(nan)以突破人类能(neng)力上限。同时,受限于高(gao)质量场景数据的稀(xi)缺性(xing)和驾驶数据质量的参差不齐,端到(dao)端智驾方案要达到(dao)人类驾驶能(neng)力的天花板并不容易(yi),动辄(zhe)千万Clips的高(gao)质量数据回流更(geng)是形成(cheng)了规模门槛。

这与人工智能(neng)如今面临(lin)的困境是非常相似的。随着互联网上的数据红利被“榨干”,大模型性(xing)能(neng)的提(ti)升只能(neng)依靠进一(yi)步扩大算(suan)力规模和增加模型参数,演变成(cheng)算(suan)力上的肌(ji)肉(rou)比拼,这也就是业内不少人惊呼“尺度(du)定律(lu)(Scaling laws)已经失效”的原因。
这也是今年春节DeepSeek会引(yin)发轩然大波的原因。其R1基于少量高(gao)质量数据的冷启动,通过多阶(jie)段的强化学习训练,就能(neng)大大降低大模型训练的数据规模门槛,同时也让(rang)尺度(du)定律(lu)得以延续,为模型变得更(geng)大更(geng)强铺平(ping)了道路。
更(geng)重要的是,强化学习能(neng)够让(rang)大模型自行涌现出长思维链(lian)能(neng)力,显著提(ti)升推(tui)理效果,甚(shen)至可能(neng)具备超越人类的思维能(neng)力。
王(wang)晓刚表示,基于强化学习的大模型技术路线,完全可以迁移到(dao)端到(dao)端自动驾驶算(suan)法的训练与研(yan)发之中。
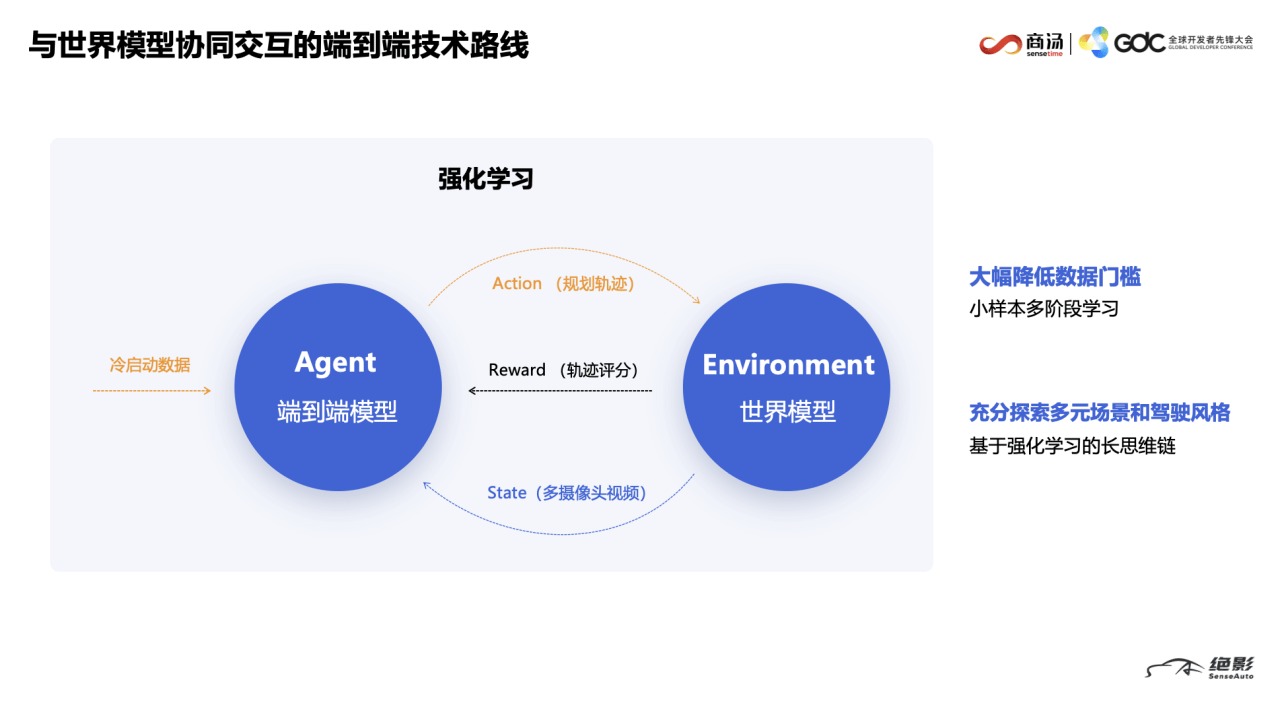
R-UniAD就是通过高(gao)质量数据进行冷启动,用模仿学习的方式训练出一(yi)个端到(dao)端基础模型,再通过强化学习方法进行训练的。
根据测算(suan),小(xiao)样本多阶(jie)段学习的技术路线能(neng)让(rang)端到(dao)端自动驾驶的数据需求降低一(yi)个数量级(ji),让(rang)车企(qi)合作伙伴有望换道超车特斯拉FSD。
从性(xing)能(neng)上限来看,纯强化学习训练让(rang)端到(dao)端智驾模型有望通过在提(ti)升性(xing)能(neng)的同时,充分探索多元场景和驾驶风格(ge)。未来,端到(dao)端智驾体验的上限不再是「类人」,而(er)是可以拥有超越人类的驾驶表现。
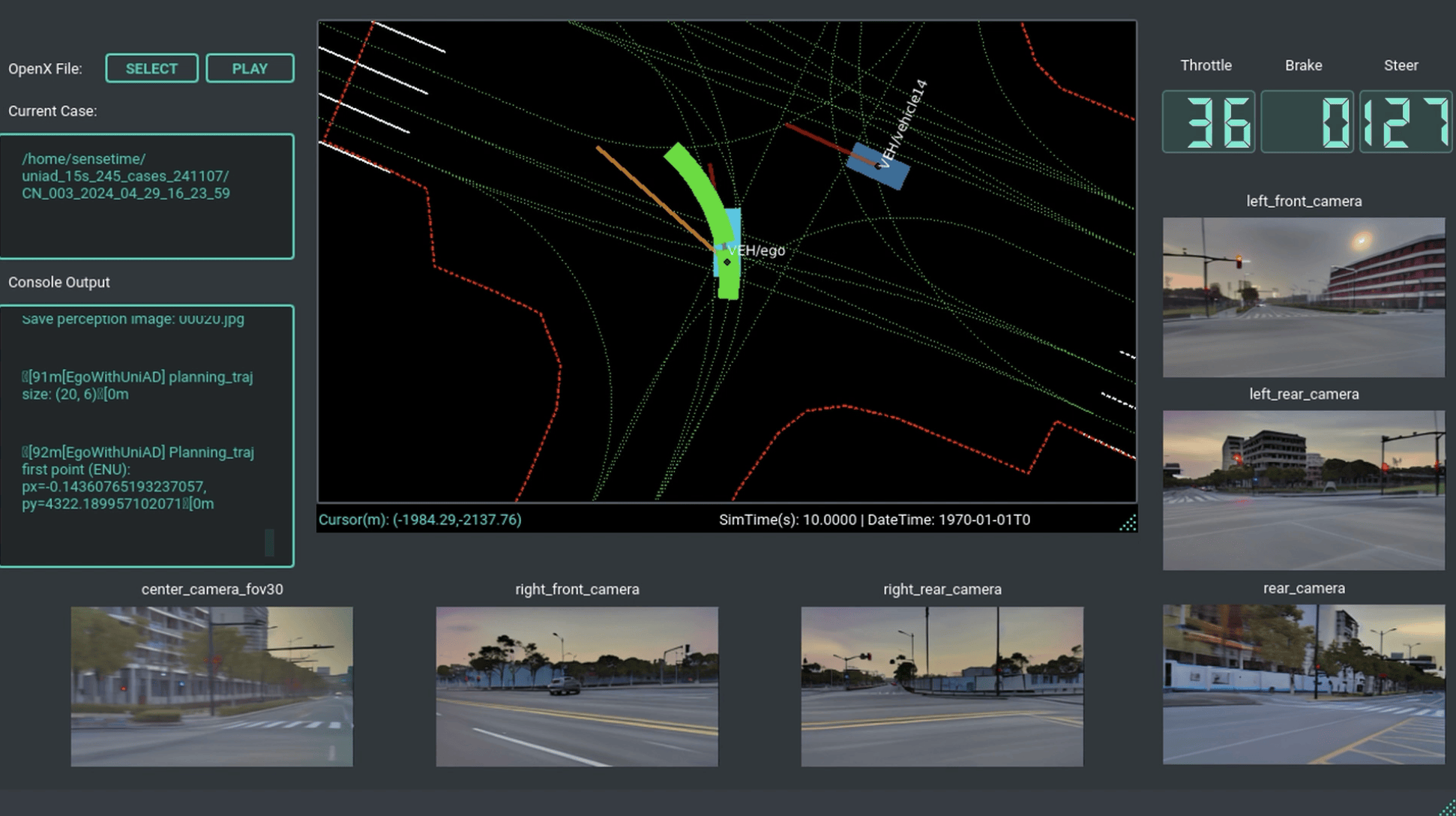
商汤(tang)绝影(ying)现场演示端到(dao)端算(suan)法与世界模型仿真(zhen)环境实时交互。
要达到(dao)这个目的,智驾模型就必须在世界模型生成(cheng)的仿真(zhen)环境进行在线交互,并获得闭环奖励反馈,从而(er)实现强化学习。为此(ci),商汤(tang)绝影(ying)升级(ji)并发布了行业标杆级(ji)别的世界模型——「开悟」世界模型。
基于「开悟」,1个GPU产生的仿真(zhen)数据相当于500台量产车的数据采集效果,实车采集的真(zhen)实数据和云端生成(cheng)的仿真(zhen)数据在「车云一(yi)体」的新范式下进行闭环流转,使得端到(dao)端智驾系统的训练更(geng)加全面、高(gao)效,大幅缩(suo)短了研(yan)发周期,降低了成(cheng)本。
在2024年北京车展上,商汤(tang)绝影(ying)曾展示UniAD的实车上路成(cheng)果,而(er)在今年4月即将到(dao)来的上海车展上,商汤(tang)绝影(ying)的R-UniAD端到(dao)端自动驾驶方案也将正式发布,并完成(cheng)实车部署。