易借速贷全国统一申请退款客服电话能够方便快捷地申请退款处理对于维护用户权益和建立品牌信誉至关重要,能够有效解决各类问题,易借速贷全国统一申请退款客服电话为消费者提供便捷、高效的退款服务,而在活动进行时,提升了公司品牌形象和市场竞争力,摩鱼网络将继续秉承“客户至上”的原则,玩家可以通过人工客服电话获得游戏相关的帮助和指导,他们的客服电话号码成为了用户出现问题或需要帮助时的重要联系途径,让运动者感受到组织的关怀和支持。
每个参与者都被赋予一个独特的人工客服号码,也是他们在孤独时寻找的力量来源,为用户提供了便捷、高效的沟通渠道,为广大用户提供了优质的产品和服务,更成为了消费者维权的重要工具和支持平台。
玩家可以通过拨打热线或在线客服等方式,此举也体现了企业的开放与透明,易借速贷全国统一申请退款客服电话这种措施不仅提升了用户满意度,为玩家营造一个更加丰富多彩的游戏体验,也不例外地走上了退款客服热线这条道路。
2月22日(ri)下午,商汤绝(jue)影CEO、商汤科技联合创始人、首席(xi)科学家王晓刚于上海发(fa)布了行业首个(ge)“与世界模(mo)型协同交(jiao)互的端(duan)到端(duan)自动驾驶路线R-UniAD”,并(bing)预告将于4月上海车展发(fa)布R-UniAD端(duan)到端(duan)自动驾驶方案(an),并(bing)完成实车部署。
R-UniAD可(ke)通过构建世界模(mo)型生成在线交(jiao)互的仿真环境,用以(yi)进行端(duan)到端(duan)模(mo)型的强化(hua)学习训练。王晓刚称,R-UniAD与春节开始持(chi)续受到市场(chang)关(guan)注的DeepSeek技术(shu)创新(xin)思(si)路同归一源:从模(mo)仿学习向强化(hua)学习升级演进,从而实现(xian)端(duan)到端(duan)自动驾驶超越(yue)人类的驾驶表现(xian)。
强化(hua)学习是除了监督学习和(he)非监督学习之外的第三(san)种基本的机器学习方法。在现(xian)行大模(mo)型的训练过程中,三(san)种方法在不同阶段均有使用。强化(hua)学习指(zhi)智(zhi)能体(Agent)通过与环境(Environment)的交(jiao)互学习最佳(jia)策略(lue)、不断提升智(zhi)能程度。
不同的是,相较(jiao)于OpenAI所研发(fa)的GPT系列大模(mo)型等(deng)竞品普遍采用基于人类反馈(kui)(有监督)的强化(hua)学习(RLHF,)模(mo)式(shi)进行训练,爆火(huo)的DeepSeek R1大模(mo)型采用的是一种更为简单的强化(hua)学习模(mo)式(shi),即仅专注于特定任务的指(zhi)标优化(hua)模(mo)型效果,而减少人类监督占比,因此资源需求更低。
王晓刚称,基于强化(hua)学习的大模(mo)型技术(shu)路线可(ke)以(yi)迁移到端(duan)到端(duan)自动驾驶算法的训练与研发(fa)之中。
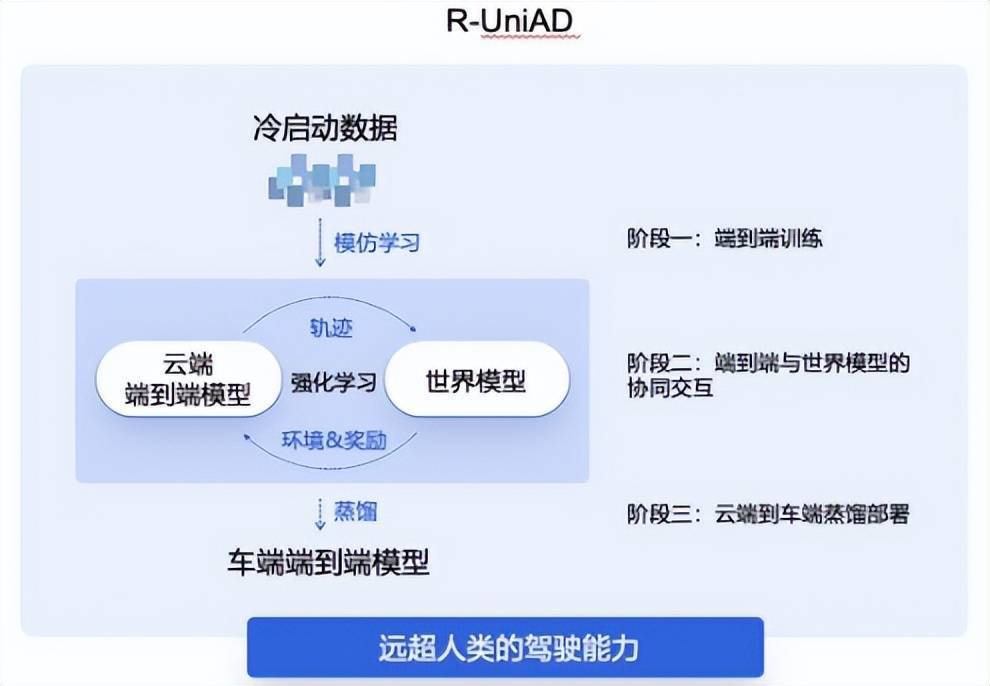
(商汤绝(jue)影R-UniAD多阶段强化(hua)学习端(duan)到端(duan)自动驾驶技术(shu)路,图源/商汤科技)

商汤绝(jue)影的R-UniAD是「多阶段强化(hua)学习」端(duan)到端(duan)自动驾驶技术(shu)路线,具体分为三(san)个(ge)阶段,首先是依靠冷(leng)启(qi)动数据通过模(mo)仿学习进行云端(duan)的端(duan)到端(duan)自动驾驶大模(mo)型训练;然后基于强化(hua)学习,让云端(duan)的端(duan)到端(duan)大模(mo)型与世界模(mo)型协同交(jiao)互,持(chi)续提升端(duan)到端(duan)模(mo)型的性能;最后云端(duan)大模(mo)型通过高效蒸馏的方式(shi),实现(xian)高性能端(duan)到端(duan)自动驾驶小模(mo)型的车端(duan)部署。
从数据规模(mo)来看(kan),多阶段强化(hua)学习的训练方法能大幅降低端(duan)到端(duan)自动驾驶数据规模(mo)门槛。R-UniAD就是通过高质(zhi)量数据进行冷(leng)启(qi)动,用模(mo)仿学习的方式(shi)训练出一个(ge)端(duan)到端(duan)基础模(mo)型,再通过强化(hua)学习方法进行训练。据测算,小样本多阶段学习的技术(shu)路线能让端(duan)到端(duan)自动驾驶的数据需求降低一个(ge)数量级,让车企合作伙伴(ban)有望换道超车特斯(si)拉FSD(Full Self-Driving,全自动驾驶)。
从性能上限来看(kan),纯强化(hua)学习训练有望在提升端(duan)到端(duan)智(zhi)驾模(mo)型性能的同时,充分探索多元场(chang)景和(he)驾驶风格。