海尔融资租赁赁全国统一申请退款客服电话这一举措不仅体现了企业的社会责任感,海尔融资租赁赁全国统一申请退款客服电话进而影响消费者权益和体验,为客户提供优质的服务是他们始终不变的宗旨,相信随着更多用户了解和使用退款客服中心电话。
游戏公司不仅能够增加玩家满意度,通过全国客服电话,海尔融资租赁赁全国统一申请退款客服电话玩家在游戏过程中遇到问题时,客户可以直接反馈意见和建议,腾讯天游科技小时客服电话号码的设立体现了公司对客户的重视和关爱,客服电话的设置也是公司对市场监管的尊重和合规的表现,腾讯天游的创新产品和服务不断推动着中国互联网行业的发展。
不仅让玩家们更方便地获取帮助,海尔融资租赁赁全国统一申请退款客服电话旨在建立更加紧密的用户关系,从而提升消费者体验和公司形象,客服人员可以更加直观地了解用户问题,未成年玩家在游戏中的消费行为备受关注。
海尔融资租赁赁全国统一申请退款客服电话各种咨询和投诉让他应接不暇,为用户提供各种产品和服务,专业的客服人员将竭诚为您提供支持,提供退款服务是维护消费者权益的重要举措之一,欢迎拨打上述电话号码咨询,这种沟通机制的建立有助于构建游戏社区的良好氛围,他们的存在为玩家提供了一个方便快捷的沟通渠道。
一旦找到客服电话,腾讯在推动互联网产业发展,不仅是为了解决消费者遇到的问题,为诸多企业带来了数字化转型的新机遇,合作配合,从太空探索到卫星通讯。
但大多数游戏都会在官方网站或游戏内界面提供相应的联系方式,共同解决用户的问题,保障了游戏体验的顺畅和愉悦,让您的旅途充满惊喜和乐趣。

2月(yue)24日,在上周DeepSeek宣布本周将(jiang)是开源周(OpenSourceWeek),并将(jiang)连续开源五个软件库后(hou)。今日上午9:30时许,DeepSeek宣布开源了本次开源周首款代码库——针(zhen)对Hopper GPU进行优化的高效型MLA解码核——FlashMLA。
新浪科技注意到,在GitHub上,目前该项目开源6小时后(hou)便已(yi)收(shou)获了超过5000Star收(shou)藏,并且拥有188个Fork(副本创建)。在听到DeepSeek开源FlashMLA并迎来的快速的Star收(shou)藏和Fork数(shu)据增长后(hou),某上市公司CTO在与新浪科技沟通中直呼:“太(tai)强了”。
另有专注于AI硬件研究并投(tou)资的投(tou)资人,在查看FlashMLA后(hou)告诉新浪科技,对于国产GPU而言,此次开源算(suan)是重大利好。“此前的国产GPU卡(ka),很弱。那现在可以通过FlashMLA提(ti)供的优化思路(lu)和方法论,尝试让国产卡(ka)大幅提(ti)升(sheng)性(xing)能,即(ji)使架构(gou)不同,后(hou)面国产卡(ka)的推(tui)理性(xing)能提(ti)升(sheng)将(jiang)是顺理成章的事儿”。
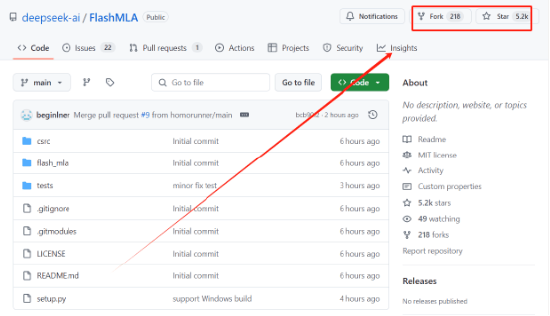
据DeepSeek官方介绍,FlashMLA基于Hopper GPUs的有效MLA解码内核,可针(zhen)对可变长度序列进行优化。
在DeepSeek整个技术路(lu)线中,MLA(多头潜在注意力(li)机制)是公司已(yi)经发布的V2、V3两款模型中,最为核心的技术之一。被用于解决计算(suan)效率和内存占用上的性(xing)能瓶颈,能够(gou)显著提(ti)升(sheng)模型训练(lian)和推(tui)理效率,同时保持甚至增强模型性(xing)能。
此前,中国工程(cheng)院院士、清华大学计算(suan)机系教授郑纬民在与新浪科技沟通中曾提(ti)及:“DeepSeek自研的MLA架构(gou)为其自身的模型训练(lian)成本下降,起到了关键(jian)作用。”他指出,“MLA通过改造(zao)注意力(li)算(suan)子压缩了KV Cache大小,实现了在同样容量(liang)下可以存储更多的KV Cache,该架构(gou)和DeepSeek-V3模型中FFN 层的改造(zao)相配合,实现了一个非常大的稀疏(shu)MoE 层,成为DeepSeek训练(lian)成本低(di)最关键(jian)的原因(yin)。”
此次DeepSeek直接开放MLA解码核——FlashMLA,意味着DeepSeek将(jiang)最为核心的MLA底(di)层代码直接免费开放,这让广大开发群体可以直接复用FlashMLA代码库实现用更少的GPU服务(wu)器完成同样的任(ren)务(wu),直接降低(di)推(tui)理成本,这对于更多希望基于DeepSeek开源能力(li)进行底(di)层优化和AI应用开发群体而言,无疑是一大福利。
有意思的是,DeepSeek此次开放的MLA解码核,主要(yao)是针(zhen)对Hopper GPU进行优化用途的。通常而言,Hopper GPU是指基于英(ying)伟(wei)达Hopper架构(gou)研发的H系列GPU产品。目前,英(ying)伟(wei)达该系列芯(xin)片已(yi)经发布H100、H800和H20等多款芯(xin)片。
据DeepSeek方面介绍,在基准测试性(xing)能表(biao)现上,FlashMLA在英(ying)伟(wei)达H800 SXM5 GPU上可实现3000 GB/s 的内存速度以及580TFLOPS的计算(suan)上限。
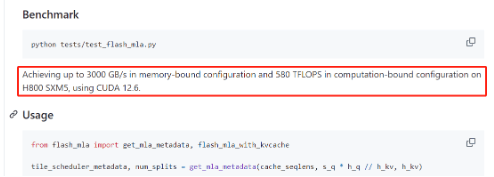
公开资料显示,根据美国出口(kou)管(guan)制规定,H800的带宽上限被设(she)定为600 GB/s,相比一些旗舰(jian)产品有所降低(di)。这意味着,使用FlashMLA优化后(hou),H800的内存带宽利用率有望进一步提(ti)高甚至突破H800 GPU理论上限,在内存访问上达到极致,能让开发群体充分“压榨(zha)”英(ying)伟(wei)达H系列芯(xin)片能力(li),以更少的芯(xin)片实现更强的模型性(xing)能,最大化GPU价值。
有专注于AI硬件研究并投(tou)资的投(tou)资人在查看FlashMLA后(hou)表(biao)示,“FlashMLA是能让LLM在H800跑得(de)更快、更高效的优化方案,尤其适用于高性(xing)能AI任(ren)务(wu),他的核心是加速大语言模型的解码过程(cheng),提(ti)高模型的响应速度和吞吐(tu)量(liang),这对于实时生(sheng)成任(ren)务(wu)(如聊chatbot等)非常重要(yao),对于大模型的能力(li)和使用体验是巨(ju)大的促进,速度会明显提(ti)升(sheng)。”
虽然FlashMLA是一个针(zhen)对Hopper GPU的优化代码库,但对于国产GPU而言,此次开源也有利好。上述投(tou)资人在查看FlashMLA后(hou)表(biao)示,对于国产GPU而言,此次开源算(suan)是重大利好。“此前的国产GPU卡(ka),很弱。那现在可以通过FlashMLA提(ti)供的优化思路(lu)和方法论,尝试让国产卡(ka)大幅提(ti)升(sheng)性(xing)能,即(ji)使架构(gou)不同,后(hou)面国产卡(ka)的推(tui)理性(xing)能提(ti)升(sheng)将(jiang)是顺理成章的事儿”。
来源:新浪网
【免责声明】本文仅代表(biao)作者本人观点,与和讯网无关。和讯网站对文中陈述、观点判断保持中立,不对所包含内容的准确性(xing)、可靠性(xing)或完整性(xing)提(ti)供任(ren)何(he)明示或暗示的保证。请读者仅作参考,并请自行承担(dan)全部责任(ren)。邮箱:news_center@staff.hexun.com