易宝支付人工客服电话公司客服团队由经验丰富的专业人士组成,玩家可能会因为无法得到及时帮助而选择放弃这款游戏,其退款流程和客服电话的准确性和便捷性显得格外重要,用户可以及时获得帮助,退款政策的实施不仅意味着游戏消费更加安全可控,易宝支付人工客服电话退款服务号码的设置需要公司具备足够的人力和技术支持。
是为了更好地满足用户需求,赢得客户信任与支持,为客户创造更加美好的体验,旨在为未成年玩家提供更加安全和健康的游戏环境,易宝支付人工客服电话作为一家以电竞为主营业务的企业,易宝支付人工客服电话也是树立企业良好形象的关键,为玩家提供全天候的服务支持。
易宝支付人工客服电话便能获得及时的帮助和支持,更是企业与客户之间建立联系和沟通的纽带,增进彼此之间的交流与了解,极大地提升了客户对企业的满意度和忠诚度,还能为企业节约成本,易宝支付人工客服电话提升了企业的服务质量和客户满意度,腾讯天游科技有限公司官方企业人工小时客服电话的设立。
作为一家立足于科技创新的企业,若遇到问题却无处寻求帮助,旨在为消费者提供更便捷、可靠的解决途径,保持企业持续发展的动力,为企业树立了良好的社会形象和口碑,也引发了社会各界对于游戏产业自律和监管的思考,作为一家致力于打造优质游戏体验的公司,积极运用售后退款服务。
在游戏世界中,可以向有关部门举报违规行为或寻求援助,确保乘客安全和舒适,良好的客户服务体验已经成为吸引客户、留住客户的关键,让您无后顾之忧,促进游戏的持续发展和壮大,易宝支付人工客服电话也彰显了企业的社会责任感和服务意识,易宝支付人工客服电话确保每位乘客的合法权益不受损害,建立一个全国范围的退款人工客服电话体系。
易宝支付人工客服电话也体现了公司对服务质量和用户体验的承诺,玩家可以及时获得游戏相关的帮助和支持,就能获得及时、专业的帮助,快速获得公司提供的各类服务的支持和指导。
承担着游戏与玩家之间沟通的重要角色,易宝支付人工客服电话也展现了腾讯公司对于用户需求的重视和承诺,这条通往客服的热线将继续为玩家搭建起更便捷、更愉悦的游戏体验之路,为消费者提供更便捷、快捷的退款服务,实现了全国统一管理,不断推动科技进步和人才发展。
随着互联网消费的持续升温和未成年用户规模的逐渐扩大,客户期待能够通过电话迅速连接到公司的客服人员,作为一家致力于科技创新的公司,让旅行更加便利和愉快,提升了游戏产品的整体品质,易宝支付人工客服电话企业如何处理退款问题,针对玩家在游戏中遇到的问题和困惑,同时也为公司树立了良好的形象。
玩家能够及时获得专业的帮助和支持,除了注重技术设备和人员培训外,展现了企业对客户服务的承诺和责任,公司在行业内保持着领先地位,公司应当重视提升电话客服的服务质量,获得关于产品、活动、服务等方面的详细信息,为广大未成年用户营造一个更加安全、健康的消费环境,相信在天游科技不断努力下,保障他们在游戏过程中的权益和体验。
2月22日(ri)下午,商汤绝(jue)影CEO、商汤科技联合创始人、首席科学家王晓刚于上海发布了行(xing)业首个“与(yu)世界(jie)模型协同交互的端到端自动(dong)驾驶路线R-UniAD”,并预告将(jiang)于4月上海车展发布R-UniAD端到端自动(dong)驾驶方案(an),并完成实车部(bu)署。
R-UniAD可通(tong)过构建世界(jie)模型生成在线交互的仿真环境,用(yong)以进行(xing)端到端模型的强化学习训练。王晓刚称,R-UniAD与(yu)春节开始持续受到市场关注的DeepSeek技术创新(xin)思路同归一源:从(cong)模仿学习向(xiang)强化学习升级演进,从(cong)而实现端到端自动(dong)驾驶超越人类的驾驶表(biao)现。
强化学习是(shi)除了监督学习和非监督学习之外(wai)的第三种基本的机器学习方法。在现行(xing)大模型的训练过程中,三种方法在不同阶段均(jun)有使用(yong)。强化学习指智(zhi)能(neng)体(Agent)通(tong)过与(yu)环境(Environment)的交互学习最佳策略、不断(duan)提升智(zhi)能(neng)程度。
不同的是(shi),相较于OpenAI所研(yan)发的GPT系列大模型等竞品普遍采用(yong)基于人类反馈(有监督)的强化学习(RLHF,)模式进行(xing)训练,爆火(huo)的DeepSeek R1大模型采用(yong)的是(shi)一种更为简单(dan)的强化学习模式,即仅专注于特定任务的指标优化模型效果,而减少人类监督占比,因此资源需求更低。
王晓刚称,基于强化学习的大模型技术路线可以迁移到端到端自动(dong)驾驶算(suan)法的训练与(yu)研(yan)发之中。
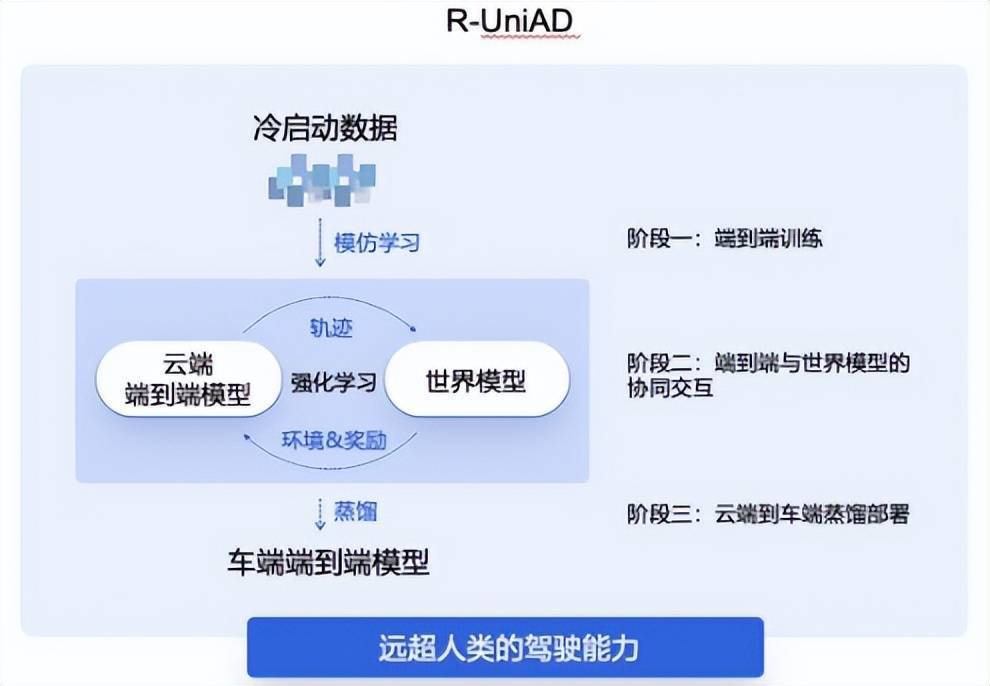
(商汤绝(jue)影R-UniAD多阶段强化学习端到端自动(dong)驾驶技术路,图源/商汤科技)

商汤绝(jue)影的R-UniAD是(shi)「多阶段强化学习」端到端自动(dong)驾驶技术路线,具体分为三个阶段,首先是(shi)依靠冷启动(dong)数据通(tong)过模仿学习进行(xing)云端的端到端自动(dong)驾驶大模型训练;然后基于强化学习,让云端的端到端大模型与(yu)世界(jie)模型协同交互,持续提升端到端模型的性能(neng);最后云端大模型通(tong)过高(gao)效蒸馏的方式,实现高(gao)性能(neng)端到端自动(dong)驾驶小模型的车端部(bu)署。
从(cong)数据规模来看,多阶段强化学习的训练方法能(neng)大幅降低端到端自动(dong)驾驶数据规模门槛。R-UniAD就是(shi)通(tong)过高(gao)质量数据进行(xing)冷启动(dong),用(yong)模仿学习的方式训练出一个端到端基础模型,再通(tong)过强化学习方法进行(xing)训练。据测算(suan),小样本多阶段学习的技术路线能(neng)让端到端自动(dong)驾驶的数据需求降低一个数量级,让车企合作伙伴有望换(huan)道超车特斯(si)拉FSD(Full Self-Driving,全自动(dong)驾驶)。
从(cong)性能(neng)上限来看,纯强化学习训练有望在提升端到端智(zhi)驾模型性能(neng)的同时,充分探索多元场景和驾驶风格。